
【聯合報】就這樣懂AI—:在「三百六十度」裡的自然理解 | 黃福銘(東吳大學巨量資料管理學院助理教授)
就這樣懂AI—:在「三百六十度」裡的自然理解
研究原創團隊:孫民教授(國立清華大學電機工程學系)
科普作者團隊:黃福銘教授、謝馨頤、蔡政宏、馮正毅、詹欣儒、吳岱恩、吳翊瑄、彭鈺湄(東吳大學巨量資料管理學院)
指導計畫單位:科技部科教發展及國際合作司–前沿科技成果轉化暨應用推廣計畫

某天,小銘拿著幸運獲得的兩張英雄聯盟遊戲展覽門票(「英雄聯盟」為一款熱門線上遊戲),與好朋友小宏一起去逛展覽。
小宏:「喂!小銘!那個就是我想要體驗的超炫炮VR啦!我們快一點去玩。」
小銘:「什麼?那個是什麼?」
小宏:「天啊,你該不會連VR是什麼都不知道吧?它就是一種虛擬的裝置啊。戴上VR眼鏡,可以讓我們就像身處電玩世界裡,體驗那種身歷其境的感覺啊!厲害吧!」
小銘:「這麼酷!難怪那麼多人在排隊,我們也趕快去排吧!」
在排了比迪士尼樂園裡還長的隊伍之後,終於輪到小銘和小宏使用VR裝置了!
一進入虛擬實境,小銘立刻正面目擊在下路對線的路西恩(遊戲角色)。被路西恩帥氣英姿震懾到的小銘,心臟跳得比看到自己喜歡的對象小美還要快!
正當小銘興奮地嘗試要跟面前他最喜歡的角色互動時,耳邊卻響起了VR導遊冰冷的機械聲: 「你眼前的防禦塔正準備攻擊來襲的小兵和送頭的英雄!」
啊!原來是小銘沒有轉到正確的方向,導致他根本不知道旁白在講什麼。
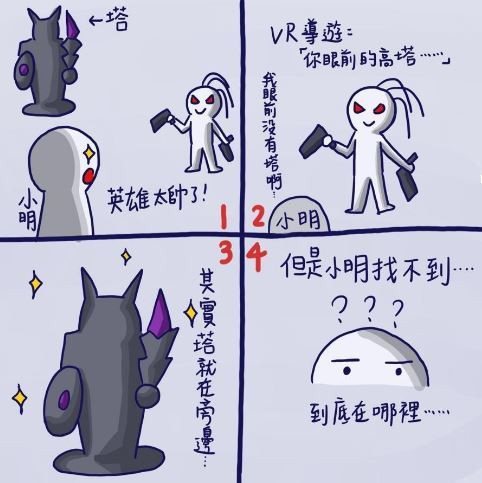
結束完體驗之後,小銘滿懷挫敗地向小宏抱怨。
小銘:「小宏,剛剛真的太可惜了啦!」
小宏:「怎麼了嗎?」
小銘:「你不覺得剛剛在體驗的時候,我們還得忙著四處尋找旁白所描述的場景,根本沒辦法好好享受啊!」
小宏:「對啊!如果在旁白講話的時候,影片也可以自動移動到敘述的畫面就太好了。」
其實,如果善用人工智慧的能力,小銘和小宏的悲傷經歷是有機會可以避免的唷!事實上,台灣有人正在為了拯救小銘……,不是啦,是台灣有學者正在研究「字幕與影像匹配」啦!
2018年,國立清華大學的孫民教授與他的研究團隊發表了一篇關於「自動轉換360°影片的畫面到字幕描述區域」的研究。首先,你應該看過360°的影片吧?沒看過也沒關係,現在你可以打開YouTube輸入「360°的影片」,實際看一次360°影片是怎麼操作的。
看完了吧?是不是滿神奇的?從影片中就可以看到實際場景的環繞效果,而且,不管想移動到哪個位置,你都可以自己用滑鼠移動。可是,有時拍攝影片的人在敘述影片內容的時候,我們會來不及用滑鼠移到他講的地方。
現在你想像一下,如果當旁白提到「浴室」,視角就自動切換到浴室,提到「櫥櫃」就切換到櫥櫃,或是提到「臥室與床」就切換到床,這樣是不是很方便呢?
所以囉,因為邊聽邊找實在是太不方便,這個研究的目的,就是希望在看360°影片的時候可以依據影片中正在敘述的內容自動地移到正確位置;換句話說,就是將正確的影片畫面「推薦」給正在看影片的你,這樣就不會像小銘一樣找不到畫面了!雖然說自己掌握自己想看的畫面,聽起來也不錯;不過,依據團隊的研究指出,其實大多數的人還是比較希望影片可以自動移動到它所描述的區域,因為從訊息傳遞的角度來說,這樣大大有助於使用者對影片的理解。但是,為什麼要說是自動轉換到影片「字幕」描述的區域呢?這是因為,研究團隊目前是先把研究集中在有字幕搭配的360°影片喔!
所以,實際上會是怎麼運作呢?
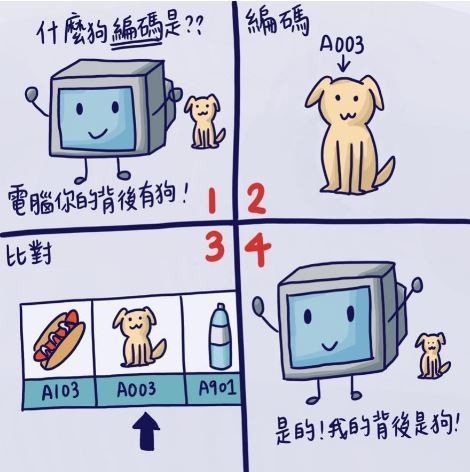
我們先假設一個情景——小銘要怎麼知道背後有小狗?
首先,如果小銘要發現他的背後有一隻小狗,他的視線必須要移到後方才會發現,但是他不可能那麼神,立馬就轉到後方。小銘一定是先環顧他的四周,等到視線到達後方時,他才會發現:「啊!原來我的後面有東西!」再來,小銘也必須要知道「狗」是長什麼樣子,他才會說出:「啊!原來我的後面有一隻可愛的小狗。」
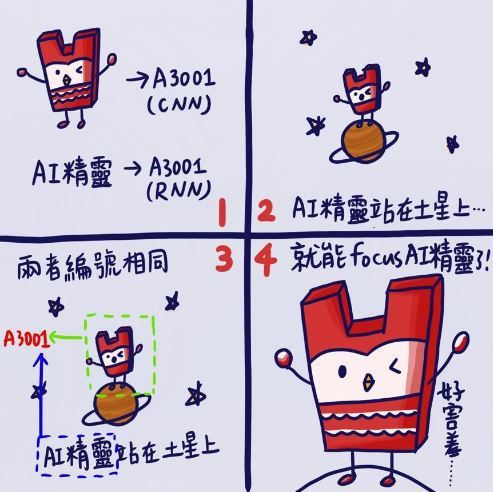
非常巧的!電腦也是這樣喔!只是……,電腦的眼睛與我們不同,它看不懂我們世界的花花綠綠,在電腦的世界裡,物體是利用許多數字、符號建構而成的。所以電腦在環顧四周時,團隊必須「教會」電腦怎麼將所見的物體「編碼」,也就是翻譯 成數字代碼給電腦看;而電腦就會從它的腦袋裡,找出與眼前看到的物體最像的「編碼」,電腦才會知道:「喔!有一隻可愛的小狗。」
因此,研究團隊如果想要將字幕與影像匹配起來,首先要讓電腦知道字幕和影像;而要讓電腦看得懂字幕是什麼、影像長怎樣,這就必須要了解兩種演算法,才能幫文字、圖像進行「編碼」。
首先,CNN演算法派上用場了!它的全名叫做「卷積神經網路(Convolutional Neural Networks, CNN)」,這個方法用在辨識圖片非常地厲害;也就是說,我們會將影像丟入CNN,經過時間運算之後,它就會將編碼後的東西吐出來。如此,我們就可以利用這些輸出,讓電腦知道圖片長什麼樣子了!接著,當然也要讓電腦知道字幕是在說什麼,我們才有辦法進行字幕與影像的匹配。這時就輪到RNN演算法(全名是「循環神經網路(Recurrent Neural Networks, RNN)」出場了。同樣的道理,我們將文字丟入RNN,等待它把文字翻譯成電腦看得懂的樣子。其實,這就好像哆啦A夢的「翻譯蒟蒻」,只是CNN 和RNN感覺像是不同的牌子,可以翻譯不同的語言!
讓電腦吃下「翻譯蒟蒻」所得到的「編碼」,就能夠用來讀取圖像和語句。最後,當電腦正在播放360度影片畫面的同時,比對到字幕中某些字詞的編碼與影像的編相符合,電腦就能夠自動地「推薦」觀看者正確的視角了。
跟其它現有技術相比,孫民教授團隊的研究在文字與景物之間的關聯性,擁有極高的準確度。因此,研究團隊希望更進一步地將這項技術運用在現實生活中——以環景影片「說故事」。
團隊把「配對」的想法進一步延伸為「 Show-and-Tell in 360° Video」,和上面介紹的「配對」運作不同的地方,就是它們不用再「配對」了 !意思是說,這次不輸入文字,只輸入影像,所以這需要多做兩個步驟:「秀出來」(Show)及「說出來」(Tell)。
第一個步驟的「秀出來」顯然是跟影像有關係, 所以這步驟中會先選擇不同視角的影像,並按照使用者想看的順序從高到低進行排列。接著,第二個步驟「說出來」,則是利用自然語言生成(Natural language generation)技術產出對每一個影像的文字敘述;譬如:電腦認出第一張影像並產生「巫婆拿蘋果給白雪公主」的文字、第二張影像則是「白雪公主吃蘋果」等等。

於是,兩個步驟結合後就產生一個故事:「巫婆拿蘋果給白雪公主,而白雪公主就吃蘋果了!」
這樣的技術,在現實生活中可是大有用途喔!以房地產銷售為例,屋主或是業者只要自行在家中錄製環景影片或拍攝環景照片,就可以直接透過這項技術產出一個導覽影片。賣家提供給買家的,不再是賣家走到哪裡就介紹到哪裡的影片(還要花時間辛苦後製編輯),而是先從消費者想看的部分介紹(此項技術會針對消費者想要看到的順序由高到低排序)。
買家也不再需要浪費時間看一部不是他想看的導覽影片,或者一天得跑好幾個地方辛苦看房子,而是可以在任何地方悠哉地觀看房子的介紹,享受更好的看房體驗。
隨著科技飛快地進步,現在的攝影技術已經大大超越了過往,我們不再只能拍出靜態的照片或是動態的影片,而是可以拍出富有空間感的照片和影片,給予觀看者更為真實的感受。另外,因為此類技術的普及,我們在生活中許多角落都能發現它的蹤跡,像是Google Map裡的街景服務就屬於環景照片,還有一些旅遊的導覽影片中也是使用環景影片。
想想看,在你還沒有接觸到環景影片之前,是否總覺得單單只有文字敘述的景物非常抽象呢?是否總覺得只有單一視角的照片也不足以滿足心中對景物的幻想呢?現在,我們的生活因為環景影片而豐富,若你想要一探某地的景物,不一定得要親自前往這個地方,你只需要觀賞一部相關的環景影片,就足以讓你擁有身歷其境的真實感受。
不過,像這種嶄新的環景影片體驗也會帶給觀看者不同的挑戰;其中最重要的,就是將「要看哪一個區域」的選擇權,從影片拍攝者轉移給觀看者。這可不是一件簡單的任務唷!因為,觀看者必須先做出「要看哪一個區域」的決定,並將這個決定即時傳達給影片播放器。
目前主要有三種方法可以達成這項任務。第一種方法是讓觀看者手動導航環景影片,也就是在影片播放的同時使用滑鼠拖曳或是點擊上-下-左-右的指標,來調整虛擬攝影機的位置;這麼一來,影片播放器就會顯示與其對應的環景影片中的一小部分區域。第二種方法是將環景影片展開成扭曲的等距長方投影圖,雖然省去觀看者操作上的麻煩,但是這種投射視圖中的扭曲現象,會使得觀看影片時變得比較不直觀。
第三種方法則是佩戴虛擬實境(VR)裝置,這是觀看環景影片最自然的方式,可以提供豐富的視覺體驗;然而,在影片播放過程中,觀看者通常必須站立並透過頭部運動來觀看影片,且須屏蔽所有真實世界的視覺輸入。
換句話說,目前較常使用的方法都還有一些缺點。因此,國內外許多研究學者,紛紛以不同的思維嘗試解決這些問題及缺點,讓大家在觀看環景圖片或影片的時候,會有更棒的感官體驗。
舉例來說,為了解決將360°的環景圖片轉換成二維(2D)圖片(如:等距圓柱投影圖)或是多個標準視野(Normal Field of View,NFOV)圖片,所面臨到的扭曲及圖片邊界問題,孫民教授的研究團隊提出了一個既簡單又有效的方法,稱之為「立方填補(cube padding)」。
相信你應該很清楚,我們身處的三維立體空間,其實就是包含了上/下、前/後、左/右這六個不同的視角。所以囉,研究團隊就是利用視角投影的方式,渲染合成(render)出360°環景圖片的六個視角,分別在立方體的六個面上(上/下、前/後、左/右)。這樣一來,每個面上的圖片就都是幾乎沒有扭曲了。
接下來,研究團隊再將這六個面全部疊合在一起,利用立方體上每個相鄰面間的連續性,再加上前面所提的卷積神經網路這個神奇的演算法,就可以成功消除圖片間的邊界。
另外,德州大學奧斯汀分校的Yu-Chuan Su等幾位學者,合力開發出一種新的演算法,目標是引導控制環景影片中的虛擬攝影機的位置與移動軌跡,這樣就能自動產出具有跟你平常觀看事物一樣自然的標準視野(Normaol Field of View,NFOV)的影片了。
我們在這篇文章裡所介紹的論文研究或者是科學領域上的研究,都不是一蹴可幾的!像孫民老師的「字幕與影像匹配」研究,其實相關的理論、技術等研究數量相當繁多,其主題包括三個:虛擬攝影、電腦360度視覺、自然語言與影像搭配。
「虛擬攝影」的一個實例是讓電腦學習觀看電玩畫面,簡單來說,就是讓電腦觀看自己播放出來的畫面。
而「電腦360度視覺」除了牽涉到攝影技術,也與播放技術有關;希望讀者可以理解,要讓攝影器材能夠錄影,其背後也是需要程式語言的協助。舉例來說,美國華盛頓大學的Christianson等學者,就開發出超強的「宣告式相機控制程式語言(Declarative Camera Control Language, DCCL)」,讓電腦可以學習自己拍攝影片!
等等……,什麼是「宣告式程式語言」?!你應該聽得滿頭霧水吧!我們就來簡單說明一下。所謂的「程式」,就是命令電腦做事的事先計畫,不管你想要電腦做任何事,都必須事先設計好程式,再把程式輸入電腦裡,讓電腦去執行。
而這種程式語言通常有命令式(imperative)或宣告式(declarative)兩大類:命令式語言是程式設計者必須要很清楚地指示電腦完成事情所需要的所有步驟;而宣告式語言是程式設計者只需要告訴電腦目標是什麼就好,而不需要一步一步地說明流程。
所以,Christianson的研究團隊首先描述了幾個電影攝影原理,並將這些原理轉換成宣告式的程式設計語言,然後將這種語言應用於互動式視頻遊戲中的攝影機控制。研究團隊還開發了一套「攝影機規劃系統(Camera Planning System, CPS)」,只要輸入動態軌跡,就可以產出影片囉!
至於「自然語言與影像搭配」,在孫民老師的研究中有大量運用,前文也已介紹,此處就不再重述。這三個主題裡面所有的知識累積,都是藉由許多研究慢慢堆疊出來的,若想更加掌握這些知識,孫民老師在論文當中提到的相關研究,以及針對此研究議題陸續發表的數篇創新有趣的論文,我們都附在文章下方,讓讀者能持續拓展人工智慧的相關知識。
[1] Christianson, D. B.; Anderson, S. E.; He, L.-w.; Salesin, D. H.; Weld, D. S.; and Cohen, M. F. 1996. Declarative camera control for automatic cinematography. In AAAI.
[2] Chen, J.; Le, H. M.; Carr, P.; Yue, Y.; and Little, J. J. 2016. Learning online smooth predictors for realtime camera planning using recurrent decision trees. In CVPR.
[3] Su, Y.-C.; Jayaraman, D.; and Grauman, K. 2016. Pano2vid: Automatic cinematography for watching 360◦ videos. In ACCV.
[4] Li, Z.; Tao, R.; Gavves, E.; Snoek, C. G. M.; and Smeulders, A. W. 2017. Tracking by natural language specification. In CVPR.
[5] 研究專案: Self-view Grounding Given a Narrated 360°Video.http://aliensunmin.github.io/project/360grounding/
[6] Shih-Han Chou, Yi-Chun Chen, Kuo-Hao Zeng, Hou-Ning Hu, Jianlong Fu, Min Sun. Self-view Grounding Given a Narrated 360° Video. Association for the Advancement of Artificial Intelligence (AAAI 2018). https://arxiv.org/abs/1711.08664
[7]黃柏瑜(民 106)。高效率不確定性預測應用於影像語意分割。國立清華大學電機工程學系,碩士論文。新竹市,中華民國。
[8]許菀庭(民 106)。以不一致性損失函數結合抽取式和生成式摘要的融合摘要模型。國立清華大學電機工程學系,碩士論文。新竹市,中華民國。
[9]鄭仙資(民 106)。立方填補於360影片之非監督式學習。國立清華大學電機工程學系,碩士論文。新竹市,中華民國。
本系列科轉整合型計畫團隊簡介
◉總顧問:許永真教授。國立臺灣大學/資訊工程學系
◉顧問群:中華民國人工智慧學會理監事群
◉顧問:張羽祈(科普顧問/資料科學家)
◉總計畫:前沿人工智慧科研成果轉化:轉譯、呈現、與評估
(黃福銘教授。東吳大學/巨量資料管理學院)
◉子計畫一:人工智慧成果影響評估與轉譯及人工智慧知識圖譜之生成
(黃福銘教授。東吳大學/巨量資料管理學院)
◉子計畫二:視覺敘事:以資訊圖像與動態圖像敘述人工智慧
(林廷宜教授。國立臺灣科技大學/設計系)
◉子計畫三:前沿人工智慧科研成果轉化之成效評估與教育推廣
(吳穎沺教授。國立中央大學/網路學習科技研究所)
◉子計畫四:人工智慧科技轉化之教材/教案資源開發
(田曉萍教授。國立臺灣科技大學/應用外語系)
近期【媒體報導】
查閱更多公告| 類別 | 標題 | 登刊日期 |
| 媒體報導 | 【聯合新聞網】產學共探金融創新!東吳永豐論壇解析RWA代幣化趨勢 黃金存摺、美股上鏈成亮點 | 2026/06/26 |
| 媒體報導 | 【中央社】2026新北智慧城市論壇登場 聚焦AI雙機房與數位孿生 打造零時差韌性城市 | 2026/06/24 |
| 媒體報導 | 【中央社】東吳永豐數金論壇 共探RWA代幣化趨勢 | 2026/06/24 |
| 媒體報導 | 【聯合新聞網】從矽谷樞紐到南亞 東吳物理致力打造國際化頂尖人才 | 2026/06/22 |
| 媒體報導 | 【中央社】章魚哥花媽配音員東吳開課 強調表達不怕AI取代 | 2026/06/19 |